Un peu de Back !
Suite à la partie qui permettait de consommer l’api de GitHub, passage du côté obscur : le back !
GraphQL.org
Le site GraphQL.org propose pas mal de ressources et pour me remettre dans le bain, j’ai parcouru les pages graphql-js.
J’aime beaucoup l’exemple “Object Types“ qui montre bien qu’il n’y a pas vraiment de magie: il faut bien implémenter les différentes “sous-champs” d’une future query…
Question: est-ce qu’il n’y a pas un risque de doubler certaines définitions entre une définition d’entités et la définition des types pour l’API ? Je suis sur qu’il doit y avoir une librairie pour çà … enfin une … JS Fatigue ?
C’est parti
Pas été facile de trouver une base pour avancer car beaucoup d’articles se basent sur une base de données “simulée” ou Prisma. Mais je préférais me baser directement sur une base de données comme SQLlite pour essayer d’avoir un maximum d’étapes. Je suis donc parti sur ce tuto qui utilise Apollo Server ce qui est assez logique avec le premier article.
Prisma
Un point sur Prisma cependant. Il s’agit d’un projet associé à GraphCool qui propose une abstraction de la base de données. L’idée est de décrire l’API et Prisma va “gérer” le lien avec le stockage.
A noter que pour le moment, j’ai l’impression que Prisma intègre en interne une base de données (MySQL) et ne permet pas la mise en place d’un lien vers une base de données existantes. Il faut passer par des imports / exports.
Mise en place
Dans le cadre du tuto, la mise en place est assez simple :
- Création des entités,
- Création du schéma (et donc redéfinition …),
- Mise en place des resolvers : là ou les choses se passent :),
N+1
Présentation
A ce stade, la simple API que nous utilisons montrent un futur souci en cas de montée en complexité. Sur la base de la query suivant :
{
allAuthors {
id
lastName
firstName
posts {
id
title
author {
id
lastName
firstName
}
}
}
}(je suis d’accord, c’est idiot de redemander l’auteur d’un post dans ce contexte mais c’est pour l’exemple).
La trace SQL donne le résultat suivant :
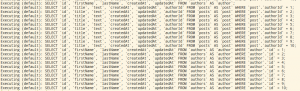
Après la requête de recherche des auteurs, l’API charge chaque liste de posts et pour chaque post, charge l’auteur. Au regard du code c’est complètement logique :
// [...]
Author: {
posts(author) {
return author.getPosts();
}
[...]
Post: {
author(post) {
return post.getAuthor();
}
}Comme chaque méthode est appelée de manière unique et que chaque méthode effectue une requête : multiplication des requêtes !
Batch
Bon évidemment, le souci est connu et a été adressé et comme d’hab, il y a plusieurs solutions disponibles mais elles tournent autour du principe de regrouper les requêtes en batch. Voici quelques librairies trouvées au hasard des recherches :
- DataLoader : librairie de Facebook qui permet de regrouper des “requêtes” et de gérer un cache,
- GraphQL Batch Resolver: alternative se voulant plus simple à DataLoader compatible également avec GraphQL.js et graphql-tools,
- [JoinMonster](http://GraphQL Batch Resolver): alternative à DataLoader mais avec une orientation plus SQL mais pas adapté à graphql-tools,
- join-monster-graphql-tools-adapter: Lien issu de la doc de JoinMonster, il s’agit d’une version fonctionnant avec graphql-tools.
DataLoader
Pourquoi :
- C’est celle qui est évoquée sur la page d’Apollo Server : ici,
- Les autres se présentent comme des alternatives : autant prendre la base.
Mise en place : les auteurs des posts
Le code suivant est basé sur le post : Batching GraphQL Queries with DataLoader. Il est adapté au contexte du projet en cours (forcément).
Il faut commencer par mettre en place un loader :
export const authorLoaders = new DataLoader(ids => {
return Author.findAll({
where: {
id: {
[Op.in]: ids
}
}
})
.then((authors) => {
const authorsByIds = _.keyBy(authors, "id");
return ids.map(authorId => authorsByIds[authorId]);
});
});Cette fonction prend en paramètre, une liste d’ids (ceux des auteurs recherchés) et appelle la fonction de recherche selon la syntaxe de Sequelize. Ensuite, il faut prendre les différents résultats et les trier dans l’ordre du tableau en paramètre. DataLoader va retourner le résultat à chaque appelant (à priori) en se basant sur l’ordre initial.
Ensuite, il faut intégrer ce loader dans le context de graphql :
graphQLServer.use(
'/graphql',
bodyParser.json(),
graphqlExpress({
schema
, context: { postsLoaders, authorLoaders }
// This option turns on tracing
, tracing: false
})
);Et finalement, il faut modifier le code d’appel pour utiliser le loader au niveau du resolver :
author(post, args, loaders) {
return loaders.authorLoaders.load(post.authorId)
.then((author) => { return author; });
},Magie !
DataLoader va intercepter les différents appels et au moment opportun, va appeler le loader qui va retourner toutes les données. Au niveau trace SQL, il n’existe plus qu’une seule requête :
Executing (default): SELECT `id`, `firstName`, `lastName`, `createdAt`, `updatedAt` FROM `authors` AS `author` WHERE `author`.`id` IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10);Mise en place : les posts
Pour les posts c’est pareil mais plus compliqué. En fait, je n’ai pas trouvé de solution en tant que tel … En effet, DataLoader propose deux méthodes :
- load: pour une entrée attend une valeur en sortie,
- loadMany: pour un tableau en entrée attend un tableau en sortie.
Dans le cas présent, le principe est d’avoir une entrée et plusieurs sorties. En effet, ici, l’idée est d’avoir les posts d’un auteur donc 1 -> N. La seule solution que j’ai trouvée est celle-ci :
export const postsLoaders = new DataLoader(authorIds => {
return Post.findAll({
where: {
authorId: {
[Op.in]: authorIds
}
}
})
.then((posts) => {
const grouped = _.groupBy(posts, "authorId");
return authorIds.map((authorId) => {
return { posts: grouped[authorId] };
});
});
});Le principe est similaire au cas précédent : le retour est groupé par authorId. Ensuite dans la fonction map, je regroupe dans un variable avec une seule propriété … Ce qui donne dans le resolver :
return loaders.postsLoaders.load(author.id).then((res2) => { return res2.posts; });Je ne suis pas sûr que ce soit la bonne méthode …
Résultats
Executing (default): SELECT `id`, `firstName`, `lastName`, `createdAt`, `updatedAt` FROM `authors` AS `author`;
Executing (default): SELECT `id`, `title`, `text`, `createdAt`, `updatedAt`, `authorId` FROM `posts` AS `post` WHERE `post`.`authorId` IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Executing (default): SELECT `id`, `firstName`, `lastName`, `createdAt`, `updatedAt` FROM `authors` AS `author` WHERE `author`.`id` IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10);A voir s’il est possible d’éviter les trois requêtes mais c’est toujours mieux que dans le cas précédent …
Liens
- Tutorial: How to build a GraphQL server
- Batching GraphQL Queries with DataLoader ,
- Optimizing GraphQL Queries with DataLoader ,
- Optimizing Your GraphQL Request Waterfalls,
- Sequelize.
Bilan
Bon après plusieurs jours sur GraphQL : quel bilan ? Le même que d’habitude : c’est un outil de plus dans la longue liste des outils possibles. Je vois bien les avantages par rapport à une API Rest mais je ne sais pas si la complexité induite est suffisante.