GraphQL
J’ai à peine compris le REST qu’on me dit que je suis déjà en retard et que maintenant, c’est GraphQL. Bon ben c’est parti …
Lecture
- http://graphql.org/
- http://graphql.org/learn/
- https://www.howtographql.com/
- Créer une application Vue avec Apollo GraphQL
- GraphQL intro - Clément Prévost - Matters meetup
- Zero to GraphQL in 30 Minutes – Steven Luscher
GraphQL Vs Rest
Premiers éléments
Issu de chez FaceBook, GraphQL est une alternative à REST pour corriger certains aspects négatifs. Un point intéressant, dans plusieurs sources, il est clairement indiqué que les personnes derrières GraphQL ont fait des choix et les assume. Il assume également les effets négatifs de ces choix. Bon je suis pas encore assez calé pour les voir mais je leur fais confiance.
Un exemple de truc: les requêtes même de lecture sont en POST … forcément pour des gens qui viennent du REST …
Un point d’entrée VS plusieurs points
La vidéo (GraphQL is the better REST) explique très bien ce point. Avec REST, il est parfois nécessaire de multiplier les requêtes et les points d’entrée pour finalement une seule demande. Avec GraphQL : une seule requête suffit.
Le client choisit
Le contenu d’un retour d’une API REST est statique (ou alors faut paramétrer). Donc parfois, on retourne trop de choses car un des clients a besoin d’une donnée. Avec GraphQL, l’API présente tout et c’est le client qui décide ce qu’il veut.
Ici, on peut se dire que finalement c’est tout paramétrable au final. Effectivement mais comme cela fait partie des fonctionnalités, il y a des règles et des moyens de faire cela “proprement”.
Fortement typés
Contrairement à REST, GraphQL est fortement typé ce qui permet de fiabiliser les différentes APIs. L’API va exposé un Schema qui peut-être vu comme un contrat (c’est le mot employé dans une présentation) entre le client et le serveur
Ici, on retrouve un principe des définitions des APIs que l’on pouvait avoir dans une WSDL. D’ailleurs, une API GraphQL est auto-descriptive permettant “normalement” la génération de client “dynamique”.
Quelques éléments clés
Spécifications
Un point important : GraphQL est avant tout une spécification. C’est ce qui m’a un peu “perdu” lors de la lecture des premiers exemples car je ne voyais pas le code. C’est “normal” si l’on veut car les explications portent sur le fonctionnement et pas l’implémentation.
Des schémas
Le schéma c’est le contrat :). Il s’agit de la définition d’une API. Le schéma est constitué de :
- Query : ce qui est exposé,
- Mutation: les actions qui sont autorisées sur les données,
- Subscription: permet au client de s’abonner à des “évènements” venant du serveur.
Resolver
Il s’agit du concept qui fait le lien entre la “Query” est l’implémentation derrière qui va récupérer les données. Chaque entrée d’une “Query” doit/peut faire l’objet d’un resolver. Sur la base d’une query du type :
query {
Beer(id: "mybeer") {
name
brewery {
name
country
}
}
}il faut les Resolvers (traduction ?) suivant:
- Beer(id: String!): Beer
- name(beer: Beer!): String!
- brewery(beer: Beer!): Brewery!
- name(brewery: Brewery!): String!
- age(brewery: Brewery!): Int!
Cela implique l’implémentation des différentes fonctions associées.
Un peu de code
Le début
Après pas mal de lecture (il est déjà tard), je commence un peu de code en suivant le tutoriel suivant : ici. Quelques infos :
- Graphcool: Un service qui propose un API GraphQL “out of the box”. Les éléments peuvent directement être publiés sur un serveur et/ou modifié en ligne. Un cloud spéciale GraphQL … Il intègre également un mécanisme de décorateur pour gérer le mapping avec la base directement (base intégrée)
- graphql-request : une toute petit librairie qui gère de manière utra simple des appels GraphSQL. A utiliser pour des choses simples
- Relay: framework client mise à disposition par FaceBook. A priori, assez complexe pour débutant,
- Apollo GraphQL : autre client GraphQL. A priori, plus simple à maitriser.
A noter qu’il s’agit d’un tuto “Client”. Donc la partie “Back” est largement géré par GraphCool qui s’occupe de mettre à disposition des Query et des mutations directement. Par exemple, la Query suivante est directement disponible sans être déclaré dans le schéma :
{
allLinks {
id
description
url
}
}GraphCool
Quelques commandes du CLI :
- graphcool-framework init [NOM]: initialise un nouveau “projet”,
- graphcool-framework deploy: déploie le projet sur le serveur de GraphCool,
- graphcool-framework playground: ouvre la console, permettant de jouer / tester notre projet,
- graphcool-framework info: affiche les infos sur le projet comme les URIs des interfaces,
- graphcool-framework add-template : GraphCool propose des templates “tout fait” pour certaines actions comme l’authentification,
Truc sympa : quand on déploie une mise à jour, GraphQL nous retourne des infos permettant de confirmer ce que l’on a fait : 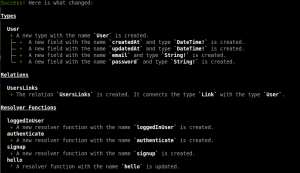
Angular / GraphQL
Encore une fois, il en faut des librairies pour faire fonctionner les différents élements :
- apollo-client: la librarie Apollo rapidement évoqué plus haut,
- apollo-angular: le binding avec Angular,
- graphql-tag: parser GraphQL. A priori, Apollo a besoin d’un parser pour pouvoir fonctionner,
- apollo-angular-link-http: permet à Apollo d’utiliser le HttpCLient d’Angular,
- apollo-cache-inmemory: gestion de cache
- graphql: implémentation de base dont se sert également Apollo
Tout cela donne la commande suivante (fourni par le tuto): npm install apollo-angular apollo-cache-inmemory apollo-client apollo-angular-link-http graphql graphql-tag
Pas été bon …
Au moment de mettre en place l’authentification, j’ai rencontré pas mal de soucis. En creusant (et j’ai creusé), je me suis rendu que le tuto est incohérent par rapport à ce qui est défini au niveau serveur par rapport à au client. Cela au niveau des signatures des mutations, des valeurs attendues et retournées. Je pense que GraphCool a du mettre à jour pas mal de choses et que le tuto lui n’a pas bougé.
Là ou j’ai pas été bon, c’est que j’ai pas noté les modifications. Je pensais avoir mis en conf avant le test mais non … donc je ne suis pas certains de toutes mes modifications. Pas bon car j’aurais pu les remonter à la personne. Le positif : je comprends mieux le fonctionnement des mutations (bien) et de GraphCool (moins bien).
Mini-Bilan
Objectivement, j’ai pas vu de grandes différences avec ce qui peut-être fait en REST au niveau de l’implémentation. J’ai eu le sentiment qu’il fallait “simplement” adapter mes connaissances au nouveau contexte (tout en se méfiant des faux amis). Mais j’ai pas senti de grosses révolutions …
Par contre, j’ai mieux compris pourquoi “QL” et pourquoi certains parlent de SQL pour le Web. En effet, en faisant choses comme celle-ci :
export const ALL_LINKS_QUERY = gql`
query AllLinksQuery {
allLinks {
id
createdAt
url
description
postedBy {
id
name
}
votes {
id
user {
id
}
}
}
}
`;L’autre point qui mériterait plus de recherches, c’est les Subscription car cela semble vraiment puissant. Je vous conseille d’aller voir l’exemple ici.
A suivre …
Après deux jours, la suite dans la partie 2.